If you have tried the Copy Activity in Azure Data Factory to copy rows of data from SQL server or SQL Pools into Delta Tables in Databricks then you may have the same problem we did. You cannot copy a SQL table to a Delta Lake table directly.
You can only use AVRO, CSV and Parquet. What Data Factory can do then is to stage this into your Lake Store and then Databricks will collect the file and load it into Delta.
The Problem An error in the Data Factory that highlights the Storage Account container cannot be accessed when trying to do a copy activity from SQL to Databricks whilst using the “staging” facility during the copy.
Unable to access container dxxxx in account stgukxxxxxx.blob.core.windows.net using anonymous credentials, and no credentials found for them in the configuration.
As you know the staging button asks you to choose a Storage Account to stage to. The problem is that Databricks will need to read from this Storage Account and therein lies the problem.
The Solution You need to add the Storage Account key to the Databricks cluster so that it can use this account key to authenticate to the Storage Account
The documentation here came in handy when my team and I were trying to understand why we were getting an error when selecting the “staging” option in a Data Factory copy activity.
The error had to do with the fs.azure.account.key that was not configured.
The Databricks settings, or so we thought
We started off this process by doing what we thought was right, which was mounting the Storage Account. If you are familiar with mounting drives for lake store folders it looks a bit like this
configs = {
"fs.azure.account.auth.type": "OAuth",
"fs.azure.account.oauth.provider.type": "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider",
"fs.azure.account.oauth2.client.id": "ee9xxxxxxxxx",
"fs.azure.account.oauth2.client.secret": "xxxxxxxxxxxxxxxxxxxx",
"fs.azure.account.oauth2.client.endpoint": "https://login.microsoftonline.com/9998877665544/oauth2/token"
}That goes in the first code block, then you put this next bit of code in the next code block
dbutils.fs.mount(
source = "abfss://bronze@mylakestoreacc.dfs.core.windows.net/",
mount_point = "/mnt/mylakestoreacc/bronze",
extra_configs = configs)This is done in the Notebook, and a Notebook is attached to a cluster.
The Factory
We had the Databricks (DBR) ready with a mounted drive, we also had a Delta table created as a Hive table. This lives in a sort of ephemeral database on our DBR worksapce.
The Data Factory has this Copy Activity which has the source as the SQL Server Database table.
The Sink side of the copy activty is a Delta type sink dataset
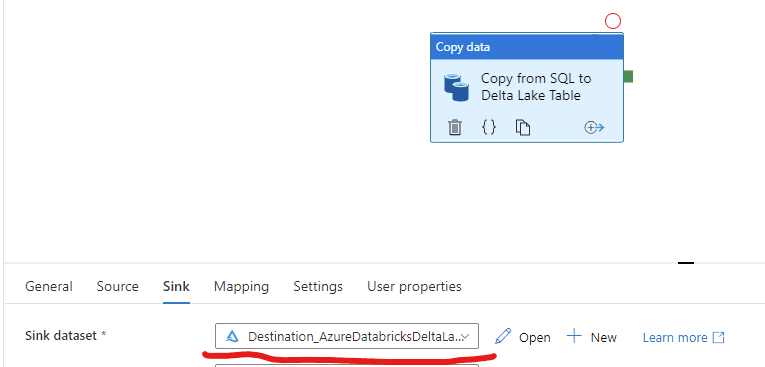
If you try to copy a SQL table directly to Delta Lake you will get an error mentioning that you should use staging to complete this task.
You can set up your staging now, select staging from the Settings tab
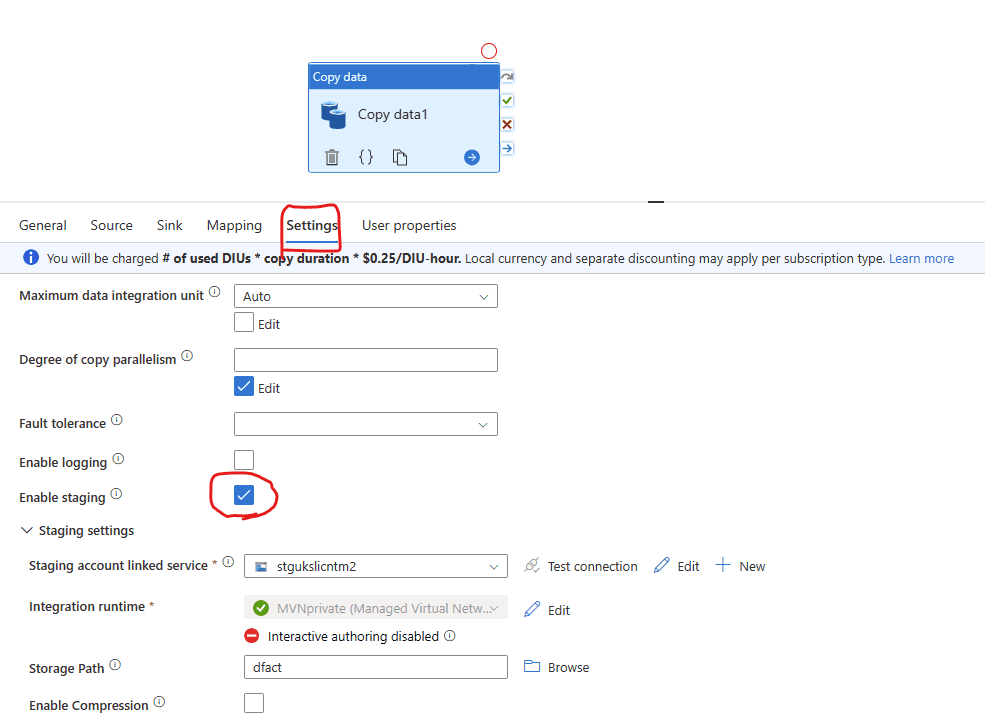
When you run this you will probably come up with this error message “Unable to access container dxxxx in account stgukxxxxxx.blob.core.windows.net using anonymous credentials, and no credentials found for them in the configuration.” or something similar
How to fix it: The Cluster has spoken - Add the Storage Account Credentials now!
There is one missing piece if you want this to work which is to have the Account Key for the Storage account registered in your Databricks cluster (in the Spark config under Advanced options in your compute).
Here are the steps to making this happen
Add a Service Principal to your Databricks
You have to set up a Service Principal (SP) for your DBR workspace. You can use Databricks CLI to do this or you can use Postman like I did. You first need to create a Personal access token in Databricks to allow authentication by third party apps. You create a token under the User Settings blade in Databricks. You can then add the SP to the databricks workspace in Postman using this token to authenticate.
RBAC things
The SP should be added to the Lake Store in the IAM (RBAC) section as a Storage Blob Data Contributor.
Create a Key Vault and make some secrets
In your Keyvault add your Service Principal App ID value and the Client Secret as separate “secrets”. You will use this for client.id and for client.secret
Add a secret to the vault that has the Access Key of the Storage Acccount that you want to mount in Databricks.
Connect your Keyvalut to your Databricks so that you can use the secrets in the notebook code
Next, create a Scope secret in the DBR. You do this by adding #secrets/createScope to the end of your databricks URL, something like this https://adb-9999988887.7.azuredatabricks.net/#secrets/createScope. Follow the prompts on this page and it will connect to your KeyVault.
Now add your Storage account key which is kept in a secret to your databricks cluster
And the last bit is to put this code in your sprak cluster config area (I like to add both dfs and blob just to be sure)
fs.azure.account.key.{{secrets/secrets4me/lzstorageacc}}.dfs.core.windows.net {{secrets/secrets4me/lzstorageacckey}}
fs.azure.account.key.{{secrets/secrets4me/lzstorageacc}}.blob.core.windows.net {{secrets/secrets4me/lzstorageacckey}}Just so you have a visual of where this is, have a look at the pic below. This should be all you need to get it to work. There is a lot of configuration, and the next bit of hard work is to CI/CD this piece of infrastructure!
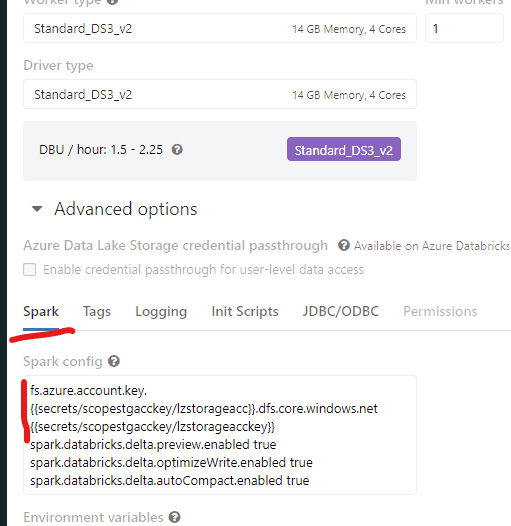
Your upgraded and better notebook code to mount the storage
Your config code can now be smarter too, you can use your keyvault secrets to hide the SP client secret
configs = {"fs.azure.account.auth.type": "OAuth",
"fs.azure.account.oauth.provider.type": "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider",
"fs.azure.account.oauth2.client.id": dbutils.secrets.get(scope="secrets4me", key="spn-dbr-testcl1-databricks-AppID"),
"fs.azure.account.oauth2.client.secret": dbutils.secrets.get(scope = "secrets4me", key = "spn-dbr-testcl1-databricks-Password"),
"fs.azure.account.oauth2.client.endpoint": "https://login.microsoftonline.com/xxxx-yourtenant-id-here-xxxx/oauth2/token"}
And better and more clever mount storage code, thanks to my friend Paul Niland for this
zone = "raw-cgroovedbricks"
mountpoint = f"/mnt/{zone}"
if mountpoint in [mnt.mountPoint for mnt in dbutils.fs.mounts()]:
dbutils.fs.unmount(mountpoint)
try:
dbutils.fs.mount(
source = f"abfss://{zone}@yourstorageaccnamehere.dfs.core.windows.net/"
, mount_point = mountpoint
, extra_configs = configs)
print(f"/mnt/{zone} has been mounted")
except Exception as e:
if "Directory already mounted" in str(e):
pass # Ignore error if aready mounted
print(f"PASS : Mount {zone} already mounted")
else:
raise e